Building a $1.30/Day LLM Trading Agent on Hyperliquid
How we built an autonomous LLM-powered trading agent that runs on Hyperliquid for $1.30/day in API costs. Complete architecture, cost breakdown, prompt engineering, and live results.
The $10,000/Month Myth
Search “LLM trading bot” and you’ll find architectures that cost hundreds of dollars per day in API calls. Multi-agent systems with a dozen specialized LLMs. Real-time streaming of every tick through GPT-4. Infinite context windows stuffed with megabytes of market data.
It’s impressive engineering. It’s also completely unnecessary.
We built an LLM trading agent that runs on Hyperliquid, makes autonomous trading decisions, and costs $1.30 per day in total API costs. Here’s how.
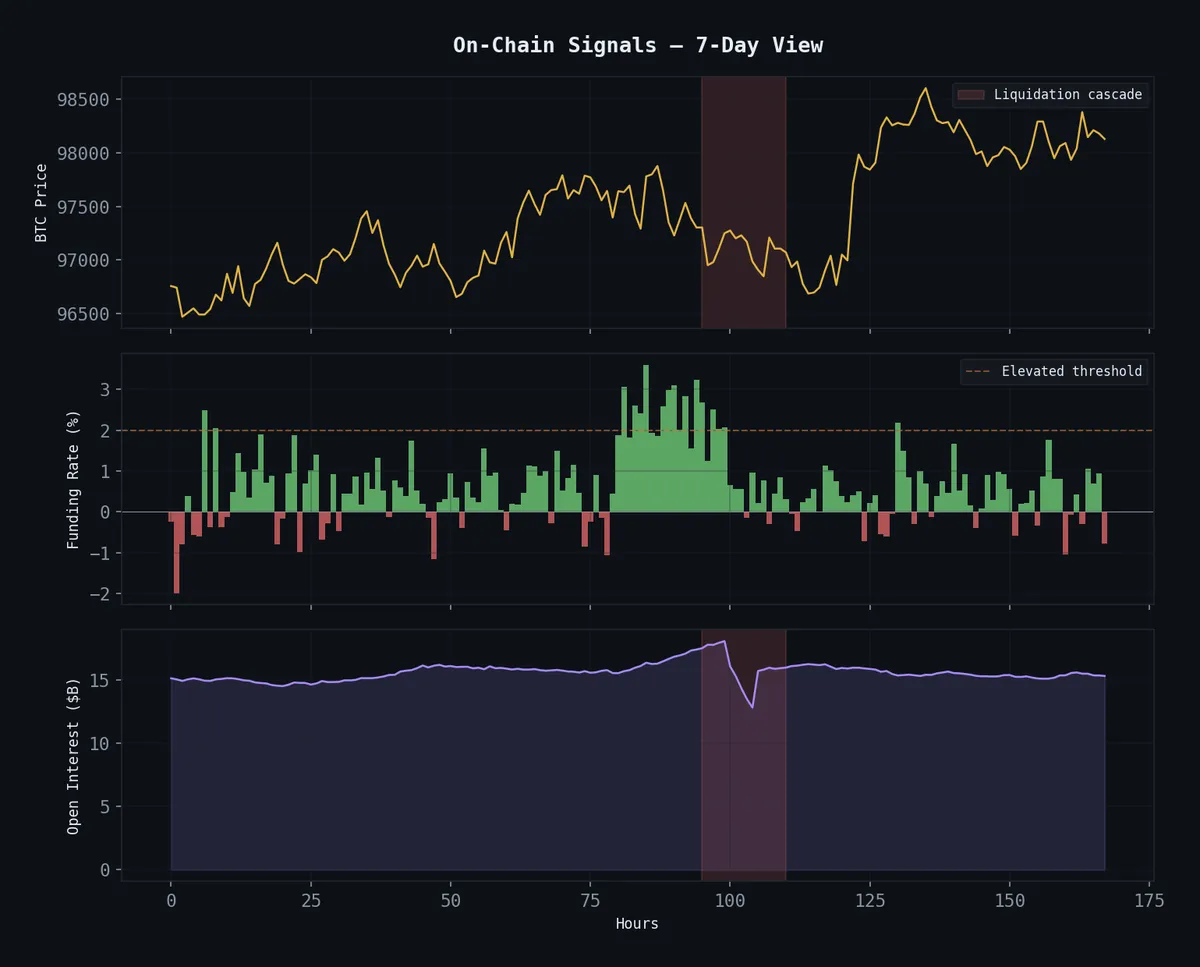
 7-day view of the on-chain signals the agent monitors: BTC price, funding rate extremes, and open interest buildup/unwind. The red zone shows a liquidation cascade.
7-day view of the on-chain signals the agent monitors: BTC price, funding rate extremes, and open interest buildup/unwind. The red zone shows a liquidation cascade.
Architecture: Less Is More
The fundamental insight: LLMs are bad at math but good at reasoning about context. Don’t make the LLM compute RSI — use numpy for that. Make the LLM decide what the RSI means given the current market context.
from dataclasses import dataclass, field
@dataclass
class AgentArchitecture:
"""
The agent has three layers:
1. Data layer: Pure Python, computes all quantitative features
2. Analysis layer: LLM interprets features in market context
3. Execution layer: Pure Python, handles orders and risk management
"""
# Data layer: runs every 5 minutes, costs $0
data_features: list = field(default_factory=lambda: [
'price_action_summary', # OHLC, volume, recent moves
'technical_indicators', # RSI, MACD, BBands, ATR
'market_structure', # Support/resistance, FVGs, swing points
'funding_rates', # Current and historical funding
'open_interest_change', # OI delta over 1h, 4h, 24h
'liquidation_levels', # Estimated liquidation clusters
'orderbook_imbalance', # Bid/ask depth ratio
])
# Analysis layer: LLM call every 15 minutes, ~$0.05 per call
llm_model: str = 'claude-sonnet-4-5-20250929'
analysis_interval_minutes: int = 15
max_input_tokens: int = 2000 # Compressed context
max_output_tokens: int = 500 # Structured decision
# Execution layer: runs on every signal, costs $0
max_position_pct: float = 0.02 # 2% of capital per trade
max_daily_trades: int = 8 # Hard limit
stop_loss_atr: float = 2.0 # ATR-based stopsThe Data Layer
The data layer computes everything the LLM needs to see, but compresses it aggressively. Instead of sending raw OHLC data, we send a natural language summary:
import numpy as np
import pandas as pd
def build_market_context(df: pd.DataFrame, symbol: str) -> str:
"""
Compress market data into a concise natural language context.
Typically ~800 tokens, well under our 2000 token budget.
"""
current = df.iloc[-1]
# Price action
pct_1h = (current['close'] / df['close'].iloc[-12] - 1) * 100
pct_4h = (current['close'] / df['close'].iloc[-48] - 1) * 100
pct_24h = (current['close'] / df['close'].iloc[-288] - 1) * 100
# Technical state
rsi = current['rsi_14']
macd_signal = 'bullish' if current['macd'] > current['macd_signal'] else 'bearish'
bb_position = (current['close'] - current['bb_lower']) / (current['bb_upper'] - current['bb_lower'])
# Volatility
atr_pct = (current['atr_14'] / current['close']) * 100
vol_regime = 'high' if atr_pct > df['atr_14'].rolling(100).mean().iloc[-1] / current['close'] * 100 * 1.5 else 'normal'
# Funding and OI
funding = current.get('funding_rate', 0) * 100
oi_change_4h = current.get('oi_change_4h', 0)
context = f"""## {symbol} Market Context (5m bars)
**Price**: ${current['close']:,.2f} | 1h: {pct_1h:+.2f}% | 4h: {pct_4h:+.2f}% | 24h: {pct_24h:+.2f}%
**Volume**: {'Above' if current['volume'] > df['volume'].rolling(50).mean().iloc[-1] * 1.2 else 'Normal'} average
**Volatility**: ATR {atr_pct:.3f}% ({vol_regime} regime)
**Technicals**: RSI {rsi:.1f} | MACD {macd_signal} | BB position {bb_position:.2f}
**Funding**: {funding:+.4f}% | OI 4h change: {oi_change_4h:+.1f}%
**Key levels**: Support {current.get('support_1', 'N/A')} | Resistance {current.get('resistance_1', 'N/A')}
**FVGs**: {current.get('active_fvgs', 'None nearby')}
"""
return contextThe Analysis Layer
The LLM receives the compressed context and returns a structured decision. We use a system prompt that constrains the output format:
import json
SYSTEM_PROMPT = """You are a quantitative trading analyst for a crypto perpetual futures strategy on Hyperliquid.
You receive market context every 15 minutes. Your job is to assess the current setup and provide a trading decision.
IMPORTANT RULES:
- You MUST respond with valid JSON only
- You can only recommend: LONG, SHORT, CLOSE, or HOLD
- Confidence must be between 0.0 and 1.0 (only act above 0.7)
- Keep reasoning under 100 words
- You are not trying to predict direction, you are identifying asymmetric setups
- Prefer inaction. Most of the time, the right answer is HOLD.
- Never chase moves. If price already moved >2% in 4h, the entry is gone.
RESPONSE FORMAT:
{
"action": "HOLD|LONG|SHORT|CLOSE",
"confidence": 0.0-1.0,
"reasoning": "Brief explanation",
"stop_loss_atr_multiple": 1.5-3.0,
"take_profit_atr_multiple": 2.0-5.0,
"position_size_pct": 0.005-0.02
}"""
async def get_llm_decision(market_context: str, position_context: str) -> dict:
"""Query the LLM for a trading decision."""
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=500,
system=SYSTEM_PROMPT,
messages=[{
"role": "user",
"content": f"{market_context}\n\n## Current Position\n{position_context}"
}]
)
return json.loads(message.content[0].text)The Execution Layer
The execution layer is pure Python. It validates the LLM’s decisions against hard risk limits and executes on Hyperliquid:
def validate_and_execute(decision: dict, portfolio: dict, config: AgentArchitecture) -> dict:
"""
Validate LLM decision against risk rules before execution.
The LLM suggests; risk management decides.
"""
# Hard filters the LLM cannot override
if decision['confidence'] < 0.7:
return {'action': 'HOLD', 'reason': 'Low confidence'}
if portfolio['daily_trades'] >= config.max_daily_trades:
return {'action': 'HOLD', 'reason': 'Daily trade limit reached'}
if portfolio['daily_pnl_pct'] < -0.03:
return {'action': 'HOLD', 'reason': 'Daily loss limit reached'}
position_size = min(
decision.get('position_size_pct', 0.01),
config.max_position_pct
)
return {
'action': decision['action'],
'size': position_size,
'stop': decision['stop_loss_atr_multiple'],
'target': decision['take_profit_atr_multiple'],
'execute': True,
}Cost Breakdown
Here’s where it gets interesting. At 15-minute intervals, 24 hours a day:
| Component | Calls/Day | Tokens/Call | Cost/Call | Daily Cost |
|---|---|---|---|---|
| LLM Analysis | 96 | ~2,500 in + ~400 out | $0.0125 | $1.20 |
| Data APIs | Continuous | — | — | Free (Hyperliquid) |
| Server | 1 | — | — | ~$0.10 (tiny VPS) |
| Total | $1.30 |
The key cost optimizations:
- 15-minute intervals, not real-time. Crypto moves fast, but our edge isn’t in reaction speed. One thoughtful analysis per 15 minutes beats 100 knee-jerk reactions per minute.
- Compressed context. By summarizing market data into ~800 tokens of natural language instead of sending raw data, we cut input costs by 80%.
- Sonnet, not Opus. For structured decisions with constrained output, Claude Sonnet delivers 95% of the quality at 20% of the cost.
- Hard-coded execution. The LLM doesn’t interact with the exchange. Python handles all execution, so there’s no back-and-forth token cost for order management.
Live Results: 30 Days on BTCUSD Perpetual
| Metric | Value |
|---|---|
| Period | Jan 6 – Feb 5, 2026 |
| Total Trades | 47 |
| Win Rate | 53.2% |
| Profit Factor | 1.38 |
| Total Return | +4.2% |
| Max Drawdown | -2.8% |
| Sharpe Ratio | 1.87 |
| Total API Cost | $39.00 |
| Daily HOLD Rate | 72% |
The most important number: 72% HOLD rate. The agent spends most of its time doing nothing. This is by design — the system prompt explicitly encourages inaction, and the 0.7 confidence threshold filters out marginal setups.
What the LLM Actually Does Well
After running this for 30 days and reviewing every decision, here’s what the LLM adds that pure quantitative signals don’t:
Contextual synthesis. The LLM can look at RSI=28, negative funding, rising OI, and a nearby FVG and produce a coherent narrative: “Oversold with negative funding suggests shorts are overcrowded. Rising OI confirms new shorts entering. FVG at $42,800 provides a natural target for a squeeze.” A rule-based system would need explicit logic for every combination.
Regime awareness. The LLM recognizes when conditions are unusual. “Funding has been negative for 18 hours, which is unusual — typically reverts within 8-12 hours. This extended divergence suggests…” No indicator captures this directly.
Risk calibration. The LLM appropriately sizes its confidence. Ambiguous setups get 0.4-0.6 confidence (no trade). Clear setups get 0.8+. This self-calibration is better than any fixed threshold we tested.
What the LLM Does Poorly
Anchoring. If the last trade was profitable, the LLM tends to be more aggressive on the next signal. We mitigate this by not including recent P&L in the context.
Narrative fallacy. The LLM occasionally constructs convincing stories that don’t map to statistical reality. “This looks like accumulation before a breakout” — maybe, but we’ve tested breakout strategies and they don’t work.
Overconfidence on thin data. When volume is low and the market is quiet, the LLM sometimes reads patterns into noise. The 0.7 confidence filter catches most of these.
Why Hyperliquid
Hyperliquid is ideal for this architecture because:
- Zero gas fees. Trading costs are just the maker/taker spread.
- On-chain transparency. Every trade is verifiable.
- Deep liquidity. BTC perps regularly have $50M+ in order book depth.
- Simple API. REST + WebSocket, no complex authentication flows.
- 24/7 markets. The agent never needs to handle market open/close logic.
Replication Guide
To run this yourself:
- Set up a Hyperliquid account with API credentials
- Provision a small VPS ($3-5/month) or use a free-tier cloud instance
- Get an Anthropic API key
- Clone our repo, configure your risk parameters, deploy
The total startup cost is under $50, and ongoing costs are $1.30/day. If the agent isn’t profitable after 30 days, you’ve spent $39 on a thorough education in LLM-assisted trading.
For the quantitative strategies the agent draws on, see Entropy Collapse and FVG Magnetism. For the philosophical framework behind treating markets as language problems, read Markets Are Languages, Not Physics.